
Data Lake is a term that has emerged in the past decade to describe an important part of the data analysis pipeline in the big data world. The idea is to create a single storage area for all the raw data that anyone in the organization may need to analyze. People usually use Hadoop to process data in lakes, but this concept is broader than Hadoop.
When I mentioned that a single point can centralize all the data that an organization wants to analyze, I immediately thought of the concept of data warehouse and data mart. But there is an important difference between data lake and data warehouse. The data lake stores raw data in any form provided by the data source. There are no assumptions about the data schema, and each data source can use any schema it likes. Users of data need to understand these data according to their own purposes.
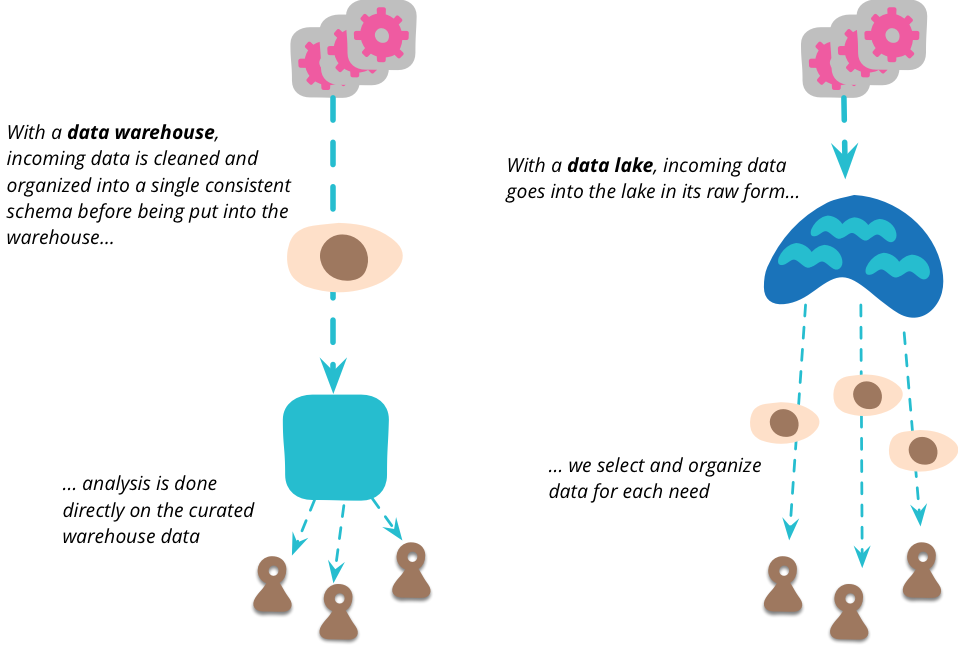
Many data warehouses have not made much progress due to the problem of patterns. Data warehouse tends to adopt the concept of single mode to meet all analysis requirements, but a single unified data model is impractical for any organization except the smallest organization. Even if you want to model a slightly complex domain, you need multiple bounded contexts, each with its own data model. In terms of analysis, each analysis user is required to use a model that is meaningful to the analysis they are conducting. By shifting to storing only raw data, this places the onus on the data analyst.
Another problem of data warehouse is to ensure data quality. Trying to obtain an authoritative single data source requires a lot of analysis on how different systems acquire and use data. System A may be applicable to some data, while system B may be applicable to other data. There are some rules that system A is more suitable for recent orders, while system B is more suitable for orders one month or earlier, unless returns are involved. The most important thing is that data quality is often a subjective problem. Different analysts have different tolerance for data quality problems, and even have different concepts of good quality.
This led to the criticism of the data lake - it is just a garbage dump of uneven quality data, or rather a data swamp. Criticism is both reasonable and irrelevant. The popular title of the new analysis is "data scientist". Although this is a title that is often abused, many of these people do have a solid scientific background. Any serious scientist knows the problem of data quality. Imagine the simple problem of analyzing temperature readings over time. It must be considered that the relocation of some weather stations may subtly affect readings, exceptions caused by equipment problems, and missing period data when the sensors are not working. Many complex statistical techniques are created to solve data quality problems. Scientists are always sceptical about the quality of data and used to dealing with problematic data. Therefore, lakes are very important for them, because they can use the original data and carefully apply technology to understand it, rather than some opaque data cleaning mechanisms that may do more harm than good.
Data warehouses usually not only clean up data, but also aggregate data into a form that is easier to analyze. But scientists also tend to oppose this, because aggregation means discarding data. The data lake should contain all the data, because it is unknown what people will find valuable, whether today or a few years later.
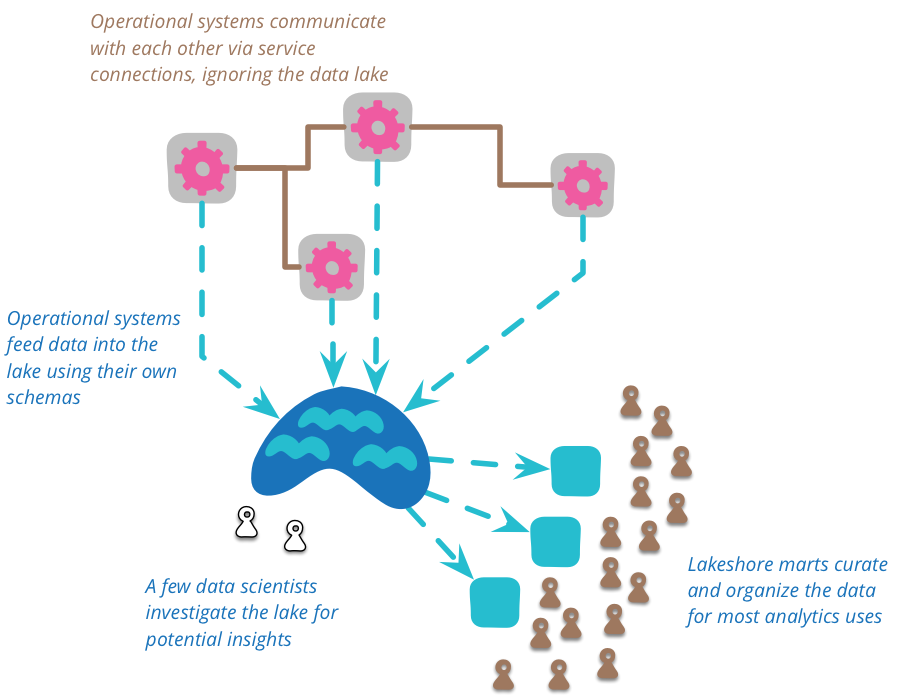
They are being modified by some month end processing reports. So in short, these values in the data warehouse are useless; Scientists fear that such comparisons cannot be made. After more mining, it is found that these reports have been stored, so the real predictions made at that time can be extracted. The complexity of this raw data means that there is space to organize the data into a more manageable structure and reduce the amount of data. Data lakes should not be accessed directly. Because data is raw data, it requires a lot of skill to understand it. There are relatively few people working in the data lake because they have found data views that are often useful in the lake. They can create many data marts, each of which has a specific model for a single bounded context. Then, more downstream users can view these marts as the authoritative source of this context.
Now, many times we have regarded the data lake as a single point for cross enterprise data integration, but it should be pointed out that this is not its original intention. This word was created by James Dixon in 2010. At that time, he intended to use the data lake for a single data source, and multiple data sources would form a "water garden". Despite the initial statement, it is now widely used to view the data lake as an integration of many sources.
We should use the data lake for analysis purposes, not for collaboration between business systems. When business systems collaborate, they should be implemented through services designed for this purpose, such as RESTful HTTP calls or asynchronous messaging.
It is important that all data put into the lake should have a clear source of time and place. Each data item should clearly track which system it comes from and when it generates data. Therefore, the data lake contains historical records. This may come from feeding business system events to the lake, or from the system that periodically dumps the current state to the lake -- this method is valuable when the source system does not have any time capability but wants to perform time analysis on its data.
The data lake is modeless. The source system decides which model to use, and consumers decide how to deal with the resulting confusion. In addition, the source system can change its inflow data mode at will, and consumers must also deal with it. Obviously, we prefer such changes to be as less disruptive as possible, but scientists prefer comprehensive data rather than missing data.
The data lake will become very large, and most of the storage will revolve around the concept of a large modeless structure - which is why Hadoop and HDFS are usually the technologies people use for data lakes. An important task of data lake fairs is to reduce the amount of data to be processed, so that big data analysis does not have to process a large amount of data.
The storage of a large amount of raw data by the data lake has caused embarrassing problems about privacy and security. The data lake is an attractive target for hackers, who may like to suck selected data blocks into the public ocean. Limiting the direct access of small data science organizations to the data lake may reduce this threat, but it cannot avoid the problem of how the organization is responsible for the privacy of the data it obtains.